1. Klasówka 2020/21 (03.12.2020)#
Zadanie 1 (8 punktów)#
Na uporządkowanym rosnąco n-elementowym ciągu \(x_1, x_2, \ldots, x_n\) dokonano dokładnie k zmian wartości elementów w tym ciągu, \(0 \le k \le n\). Ciąg otrzymany w ten sposób nazywamy k-zaburzonym.
Przykład
Uporządkowany ciąg \(\langle 2,6,8,12,21 \rangle\). Po zmianach wartości elementów - pierwszego na 7 i czwartego na 1 - dostajemy ciąg 2-zaburzony \(\langle 7,6,8,1,21 \rangle\).
Dana jest liczba całkowita k, \(0 \le k \le n\), oraz k-zaburzony ciąg \(x = \langle x_1, x_2, \ldots, x_n\rangle\). Interesuje nas wydajne sortowanie ciągu x ze względu na porównania.
[3 punkty] Zaproponuj optymalne sortowanie ze względu na porównania dla k = 1 oraz
[1 punkt] n = 4
[2 punkty] n = 5
[5 punktów] Zaproponuj asymptotycznie optymalny algorytm sortowania k-zaburzonych ciągów n-elementowych. Pamiętaj o uwzględnieniu obu parametrów - n i k.
Podpowiedź
Ograniczenie dolne:
Dla ciągu 1-zaburzonego długości n, jego permutacją kanoniczną nazwiemy permutację liczb od 1 do n otrzymaną przez przenumerowanie kolejnych co do wartości liczb ciągu kolejnymi liczbami \(1,\ldots,n\). Jeśli w ciągu 1-zaburzonym są równe elementy, numerujemy je kolejnymi liczbami w jakikolwiek sposób. Np. dla ciągu 2,6,3,7,10 permutacją kanoniczną jest 1,3,2,4,5.
Liczba permutacji kanonicznych jest równa \(n^2-2(n-1)\). Na n sposobów wybieramy, które n-1 pozycji tworzy ciąg rosnący. Na pozostałej pozycji możemy wybrać element na n sposobów. To daje \(n^2\) permutacji, przy czym permutacja rosnąca zostanie wygenerowana n razy, a każda z n-1 permutacji typu \(1,\ldots,k-1,\,k+1,k,\,k+2,\ldots,n\) - dwukrotnie. Np. dla n = 4 mamy permutacje kanoniczne: identyczność: (1) 1,2,3,4; ostatni element zaburzony: (2) 1,2,4,3; (3) 1,3,4,2; (4) 2,3,4,1; przedostatni element zaburzony: (5) 1,3,2,4; (6) 2,3,1,4; drugi element zaburzony: (7) 1,4,2,3; (8) 2,1,3,4; pierwszy element zaburzony: (9) 4,1,2,3; (10) 3,1,2,4.
Każda permutacja kanoniczna wymaga innego posortowania elementów (jeśli nawet powstała z ciągu z powtórzeniami, to powstaje też z jakiegoś ciągu bez powtórzeń). Stąd ograniczeniem dolnym na liczbę porównań wymaganych do posortowania n-elementowego ciągu 1-zaburzonego jest \(\lceil \log_2 (n^2-2(n-1)) \rceil\). W przypadku n = 4 daje to 4 porównania, a w przypadku n = 5 daje to 5 porównań.
a.1. (n = 4) Ograniczenie górne: Oznaczmy kolejne elementy ciągu przez a, b, c, d. Najpierw porównujemy b z c i w razie czego zamieniamy; wynikowy ciąg to a, \(b'\), \(c'\), d. Teraz porównujemy a z \(b'\). Jeśli \(a<b'\), to mamy rosnący ciąg 3 elementów i możemy wstawić w niego d za pomocą 2 porównań (wyszukiwanie binarne). Razem wyszły 4 porównania. Jeśli zaś \(a>b'\), to wiemy, że któryś z elementów a, b został zaburzony (tj. zmieniony); w szczególności d nie został zaburzony, więc jest maksimum. Porównujemy a z \(c'\), co pozwala nam posortować elementy a, b, c; element d ustawiamy na końcu. W tym przypadku wyszły 3 porównania.
a.2. (n = 5) Ograniczenie górne: Oznaczmy kolejne elementy ciągu przez a, b, c, d, e. Najpierw porównujemy a z b. Jeśli \(a<b\), to element a nie został zaburzony. W takim razie elementy b, c, d, e tworzą ciąg 1-zaburzony, który możemy posortować za pomocą 4 porównań za pomocą punktu a.1.; element a ustawiamy na początek. Łącznie mamy 5 porównań. Jeśli zaś \(a>b\), to jeden z elementów a, b został zaburzony. To oznacza, że elementy c, d i e są uporządkowane rosnąco. Możemy wstawić każdy z elementów a, b osobno do uporządkowanego ciągu c, d, e za pomocą 2 porównań (wyszukiwanie binarne). Jeśli te dwa elementy trafią w jedno miejsce, to o ich ustawieniu decyduje wynik pierwszego porównania. Znów łącznie wychodzi 5 porównań.
b. W czasie \(O(n)\) można rozdzielić wejściowy ciąg na dwa rozłączne podciągi A oraz X (\(|A|+|X|=n\), \(|X|\le 2k\), \(|A|\ge n-2k\)), gdzie A jest uporządkowany rosnąco, a X zawiera zaburzone elementy (i trochę nadmiarowych).
S := pusty stos
X := []
for i:= 1 to n do:
if !empty(S) and top(S) > a[i]:
{ jeden z elementów [top(S), a[i]] jest zaburzony - dla pewności dodajemy oba}
X := X + [top(S), a[i]]
pop(S)
else:
push(a[i])
A := elementy stosu S
Gdy już mamy wyznaczone zbiory A i X wystarczy
posortować elementy z X (co zajmuje czas \(O(k\log k)\))
scalić uporządkowany ciąg A z (uporządkowanym) X (co zajmuje czas \(O(n)\))
Całkowita złożoność to \(O(n + k\log k)\).
W modelu porównań ten algorytm jest optymalny, co możemy udowodnić za pomocą redukcji z problemu sortowania. Dowolny ciąg C długości k możemy zamienić w ciąg k-posortowany długości n, dopisując do niego n-k kolejnych liczb większych od jego maksimum. Posortowanie wynikowego ciągu da przy okazji posortowany ciąg C, więc nie da się tego zrobić w czasie \(o(k \log k)\).
Zadanie 2 (4 punkty)#
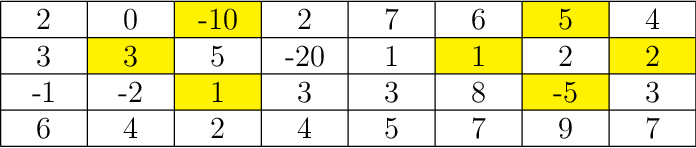
Niech \(A[1\ldots 4,1\ldots n]\) będzie tablicą liczb całkowitych. Powiemy, że dwa elementy tablicy - \(A[i,j]\) oraz \(A[i’,j’]\) - są sąsiednie, jeśli ich współrzędne różnią się o 1 na dokładnie jednej pozycji. Podzbiór elementów tablicy nazywamy rozproszonym, gdy nie ma w nim elementów sąsiednich. Wagą podzbioru elementów w tablicy nazywamy sumę zawartych w nim elementów. Zaprojektuj wydajny algorytm, który dla danej tablicy A znajdzie podzbiór rozproszony o największej wadze.
Przykład
Tablica z zaznaczonym pewnym zbiorem rozproszonym o wadze -2.
Podpowiedź
Programowanie dynamiczne.
Stan to para \((j,m)\) przy czym j to numer kolumny (od 1 do n) a m to maska bitowa rozmiaru 4 (czyli liczba z zakresu od 0 do 15 której bity określają, które elementy z j-tej kolumny wybieramy do podzbioru rozproszonego). Maska m nie może mieć dwóch kolejnych bitów zapalonych.
Wartość dla stanu to maksymalna waga podzbioru rozproszonego wybranego z pierwszych j kolumn tablicy, który w j-tej kolumnie wybiera liczby określone przez maskę m.
Z każdego stanu \((j,m)\) jest mniej niż 16 przejść, do stanów \((j+1,m')\) takich że maska \(m'\) nie ma żadnych dwóch kolejnych bitów zapalonych i maski m i \(m'\) nie mają żadnego wspólnego bitu zapalonego. Na koniec bierzemy maksimum z wyników dla stanów z j = n.
Jest \(O(n)\) stanów i przejść. Czas liniowy.
Zadanie 3 (5 punktów)#
Dany jest zbiór S zawierający n różnych punktów \((x,y)\), gdzie \(x \in \{0, 1, \ldots, n\}\), \(y \in \{0, 1, \ldots, n\}\). Zaprojektuj wydajny algorytm znajdujący wszystkie punkty \((a,b)\) w zbiorze S takie, że każdy punkt \((c,d)\) z S różny od \((a,b)\) ma mniejszą co najmniej jedną współrzędną, tzn. \(a > c\) lub \(b > d\).
Podpowiedź
Powiemy, że punkt \(Q=(c,d)\) dominuje punkt \(P=(a,b)\) jeśli \(c \ge a\) i \(d \ge b\). Chcemy wypisać wszystkie punkty ze zbioru S, których żaden inny punkt ze zbioru nie dominuje.
Posortujmy punkty ze zbioru S według współrzędnych x; jeśli jakieś punkty mają tę samą współrzędną x, zostawiamy tylko jeden z nich, o maksymalnej współrzędnej y. Sortowaniem kubełkowym i algorytmem wyszukiwania maksimum robimy to wszystko w czasie \(O(n)\).
Następnie wykonajmy następujący algorytm korzystający ze stosu. Utrzymujemy niezmiennik, że stos zawiera wszystkie punkty niezdominowane w zbiorze dotychczas rozważonych. Punkty na stosie będą posortowane po rosnących x i malejących y.
Q := pusty stos punktów
for each punkt (x, y) w podanej kolejności do:
while !empty(Q) and top(Q).y <= y:
pop(Q)
push(Q, (x, y))
return Q
Algorytm działa w czasie \(O(n)\), gdyż liczba usunięć ze stosu nie przekracza liczby wstawień, których jest co najwyżej n.
Zadanie 4 (3 punkty)#
Dany jest nieskierowany graf \(G = (V,E)\) z dodatnimi wagami na krawędziach i wyróżnionym wierzchołkiem źródłowym s. Zmodyfikuj algorytm Dijkstry w taki sposób, żeby dla każdego wierzchołka v wyznaczał wagę najlżejszej ścieżki z s do v oraz liczbę różnych ścieżek z s do v o tej wadze.
Podpowiedź
Niech d(v) oznacza odległość z wierzchołka s do wierzchołka v a c(v) oznacza szukaną liczbę różnych ścieżek długości d(v) z s do v. W trakcie działania algorytmu Dijkstry z s zapisujemy na liście wierzchołki w kolejności usuwania ich z kolejki priorytetowej. Następnie w tej kolejności będziemy im przypisywać wartości c(v).
Początkowo \(c(s)=1\). Dalej dla każdego wierzchołka v z listy, c(v) to suma wartości c(u) dla wszystkich wierzchołków u takich że \(d(v)=d(u)+w(u,v)\), przy czym w(u,v) to waga krawędzi z u do v. Z własności algorytmu Dijkstry i dodatniości wag krawędzi wynika, że w momencie rozważania wierzchołka v, wszystkie wierzchołki u spełniające ten warunek zostały już rozważone.
Złożoność jest taka jak algorytmu Dijkstry, czyli w najlepszym razie \(O(|E|+|V| \log |V|)\).